




To date, very few collective agreements include specific articles on workers’ data rights. So we need to first ask, what should these data rights cover? The figure below depicts what I call the data life cycle at work and provides the grounds on which unions should intervene to improve workers’ rights.
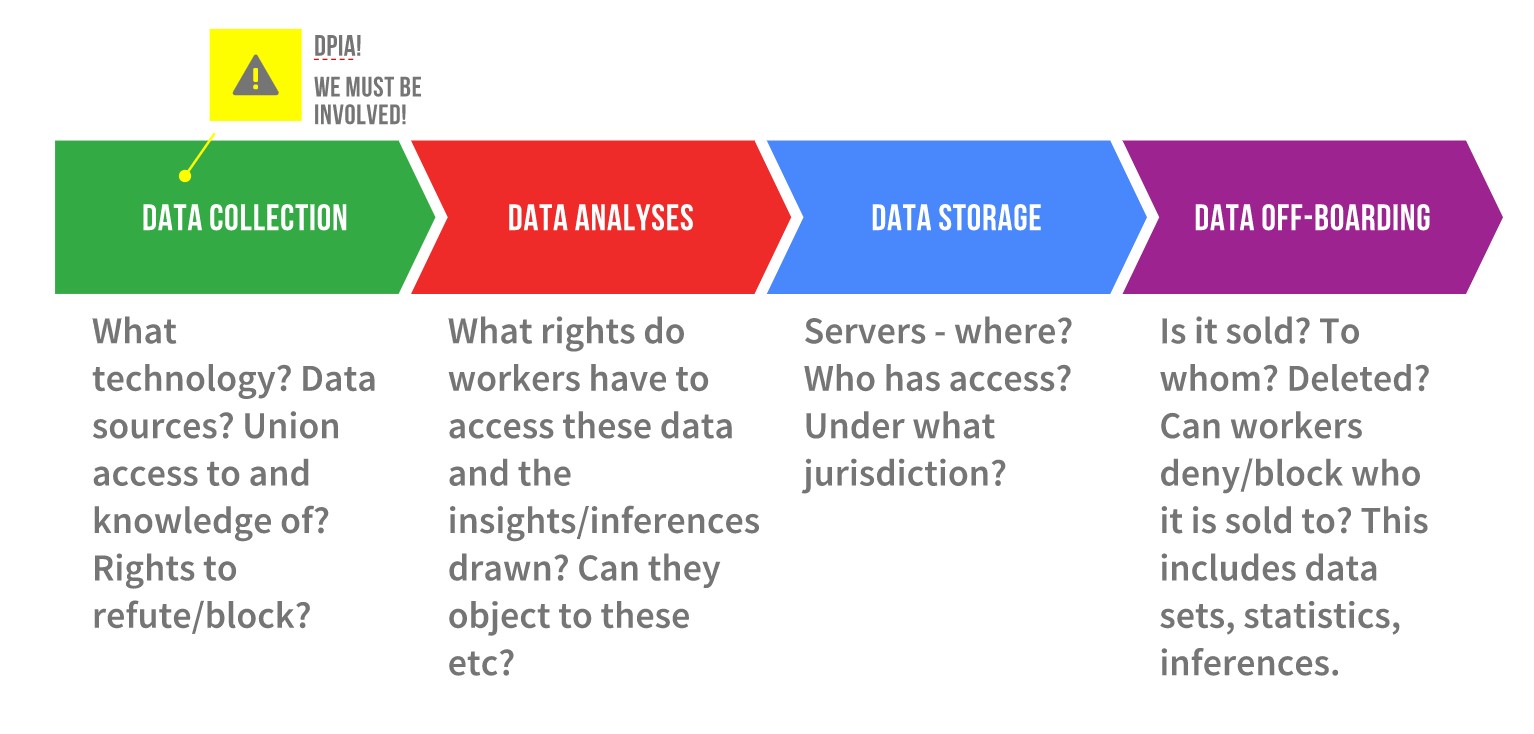
Figure 1: the Data Life Cycle at Work, by Christina Colclough
The data collection phase covers both internal and external data collection tools, sources of the data, whether shop stewards and employees have been informed about the intended tools, and whether they have the right to refute or block (parts of) said tools and their data sources. In addition, unions should demand that the shop stewards, on behalf of a worker or group of workers, gain access to the data/datasets and inferences that include employee data or personally identifiable information.
In the data analyses phase, unions must cover the gaps in current regulation and ensure rights with regards to the inferences – profiles, statistical probabilities, etc. – made using algorithmic systems and datasets. Workers should have greater insight into, access to, and rights to rectify, block or even delete inferences made about them. Since these inferences can be used to determine work scheduling and wages (if linked to performance metrics), or can leveraged by human resources to decide who to hire, promote, or fire, access to them is key to the empowerment of workers.
Data storage might at first glance seem boring, but it is actually really important, and will become even more so if current e-commerce negotiations within and on the fringes of the World Trade Organization (WTO) are actualized.16 These discussions go far beyond facilitating the buying and selling of online goods and services and propose the following: a) prohibiting data localization, which means that data, by law, cannot be required to be stored under the jurisdiction of the home country; b) establishing corporate right to transfer data across borders and store such information wherever they want, including in data havens; c) banning governments from demanding disclosure of source codes and algorithms, even in cases where it may be necessary for security reasons. (For a full list of proposals, see page 17-18 of this report by Deborah James.)
To put it simply, these proposals say that data must be allowed to be moved across borders to what, we can expect, will be areas which have the least privacy protection. They will then be used, sold, rebundled, and sold again in whatever way corporations see fit. The recent European Court of Justice ruling 17 which invalidates the EU-US Privacy Shield can be seen as a slap in the face of proponents of unrestricted flow of data, but the demand is nonetheless still on the table.
Finally, the data off-boarding phase is also one where workers and unions must be vigilant. Off-boarding refers to the deletion of data, but also the selling or passing on of data and inferences/profiles/datasets to third parties. Unions should negotiate for much better rights with regards to: a) knowing what data/datasets/inferences are off-boarded, b) who they are off-boarded to, and c) objecting to the off-boarding to third party(ies) and even blocking it. The need to negotiate these rights acquire great urgency in light of the e-commerce negotiations within the WTO (but also in other plurilateral trade negotiations). As Shoshana Zuboff asserted in her speech at Rightscon 2020:
In the above, we have established a two-step process towards empowering workers across the world in the digital economy. We need stronger workers’ rights to data and sound structures that will allow us to collectivize that data. To realize these benefits, behavioral, legal, and technical changes will need to be made. We will need to overcome our own lethargy, form new habits, establish new laws and new authorities at the national and global level. We will need new governance structures, technological solutions for secure data portability,22 and conscious choices about which collectives we will entrust with our data. These are daunting requirements. So what are the benefits?
To begin with, this will allow us to create an alternative digital economy where data is regarded as an infrastructure similar to roads, railway lines, water supplies, and energy. We will vastly reduce Big Tech’s control over our minds, emotions, actions – past and future. We might well succeed in actualizing Shoshana Zuboff’s demand that human futures markets be made illegal. We will ensure that information that is ours becomes responsibly useful to us. Trade unions across the world will get an additional and timely purpose, and we could expect greater mobilization towards this. We will undo the colonizing effects of the current e-commerce discussions and the skewed digital hegemonies and support, not hinder, the development of empowering digital transformations.
On a more practical level, we will pool resources such that we actually have access to persons with the skills and knowledge to protect our data on the one hand, and analyze it to our benefit, on the other. Digital storytelling and visualizations are a powerful means to campaign for change. At the MIT Media Lab, Dan Callaci analyzed and compared data from a WeClock trail in New York to show how often, on the same day, workers were within six feet of one another (see figure 2 below). Used in the context of the pandemic, this could show the relative risk for workers at the workplace.
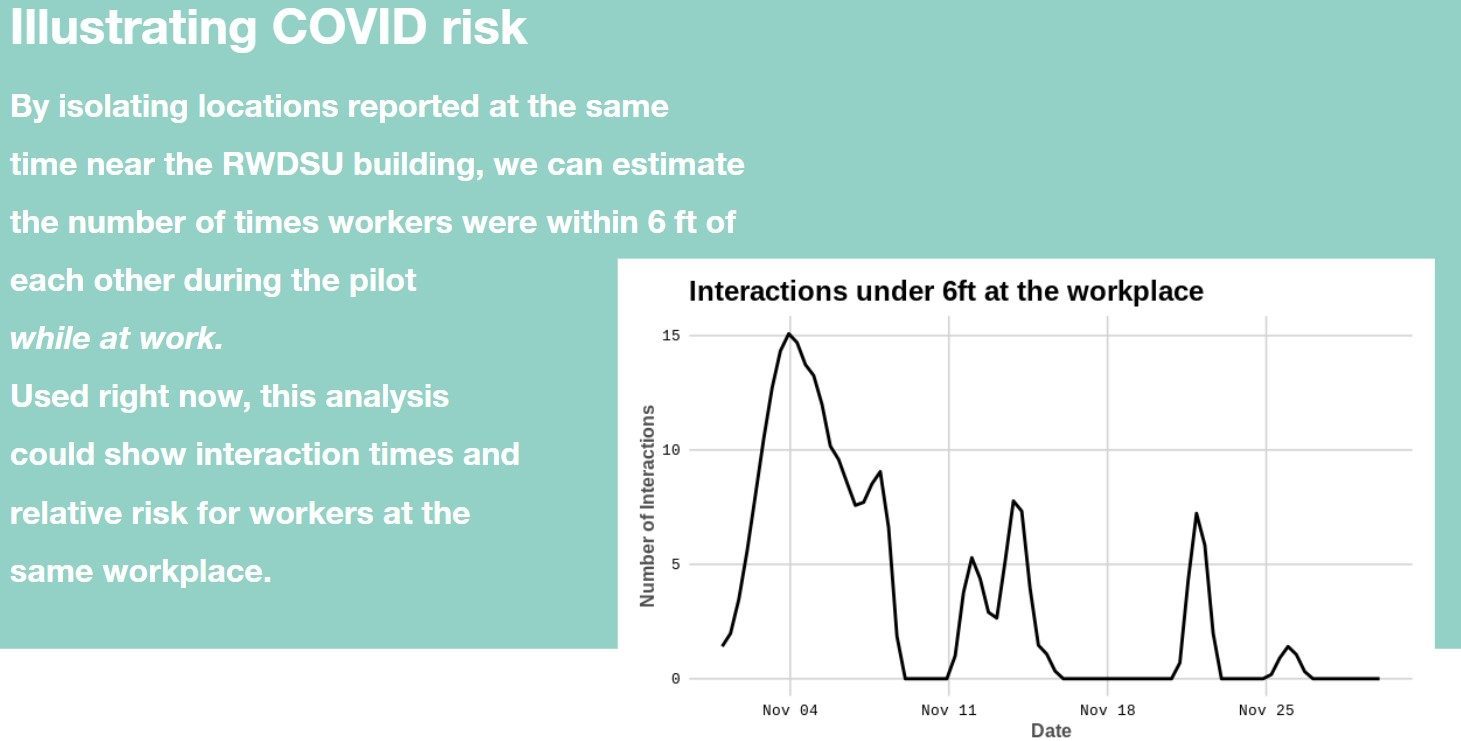
Figure 2: Dan Callaci’s analysis of workers’ data from a WeClock trail in New York.
The benefits do not stop there. The Workers’ Data Collective, like Driver’s Seat, could be used to test and challenge corporate algorithms. It will empower us as individuals and communities if we know who has our data and for what purpose(s).
The data collective could democratize the digital economy and empower workers to form and shape the world of work, advocate for regulatory change, and find remedies for persistent injustices. This will allow us to stop being “users” of digital technology, steered, controlled, and manipulated by algorithms and, instead, reclaim our humanity. This includes, not least, our human rights, our freedom of association, assembly, expression, thought, belief, and opinion.
Many data protection regulations across the world, even those aimed exclusively at consumers, are weak. We must fight for a digital ethos that is responsible and puts our rights above profit-seeking surveillance tools and predictive analytics. In the world of work, unions must be the guardians of this alternative ethos, and themselves become stewards of good data governance. Here an ILO Convention advocating for workers’ data rights will not only be an act of solidarity with workers in weaker institutional environments, but also a necessary step to prevent digital colonialism.
